~8 min read
Did You Train on My Voice? Exploring Privacy Risks in ASR

TL;DR
This post explores a recent research paper on membership inference attacks targeting Automatic Speech Recognition (ASR) models. It breaks down how subtle signals like input perturbation and model loss can reveal whether a voice recording was used during training, helping to check for privacy and compliance concerns. For cybersecurity professionals, we highlight why machine learning models should be treated as potential attack surfaces.
Introduction
Every employee at Neodyme gets dedicated time for self-directed research. I spent some time looking at automatic speech recognition models and their privacy implications 😀
In cyber security, we’re used to the idea that systems can leak information; not always through direct breaches, but also through careful observation. Timing attacks, side channels, packet size patterns… all these are important attack vectors in offensive security.
But what if the thing leaking data is a machine learning model? And worse: what if it’s a voice recognition model trained on sensitive audio?
That’s exactly a risk explored in our recent paper: “Exploring Features for Membership Inference in ASR Model Auditing” by Teixeira, Pizzi, Olivier et al. It’s a dive into how automatic speech recognition (ASR) systems might unwittingly reveal whether specific recordings (or even individual speakers) were part of the training data.
Technical Background
Let’s start with some technical background to introduce all relevant words and concepts.
Automatic Speech Recognition (ASR)
Automatic speech recognition (ASR) refers to the technology that transcribes spoken language to text. It’s what powers virtual assistants, real-time transcription services, or customer service bots (though, hopefully, you don’t have to use them too often). Modern ASR systems rely on deep learning models trained on large datasets of recorded speech from many different sources to cover a wide range of potential input data. However, some data may potentially be used even without the speakers’ explicit consent.
Membership Inference Attack (MIA)
A membership inference attack (MIA) is where an adversary tries to determine if a particular input was part of a model’s training dataset. In the context of ASR, this means checking whether a recording of someone’s voice was used to train the model.
Why does this matter? Because in many cases, especially with medical, legal, or voice assistant data, just knowing someone’s data was used may be a privacy violation. Under laws like GDPR, that may be a problem.
We’re not just talking about theoretical issues either. In the same way side-channel attacks exploit subtle shifts in behaviour, MIAs exploit differences in a model’s confidence or output when it sees familiar versus unfamiliar data.
So, how do MIAs work?
To carry out a membership inference attack (or a model audit), one needs three models: a target model (the model under test), a so-called shadow model, and a classifier. The shadow model is trained on a dataset that is similar to the target model’s training dataset. The purpose of the shadow model is to simulate the behaviour of the target model.
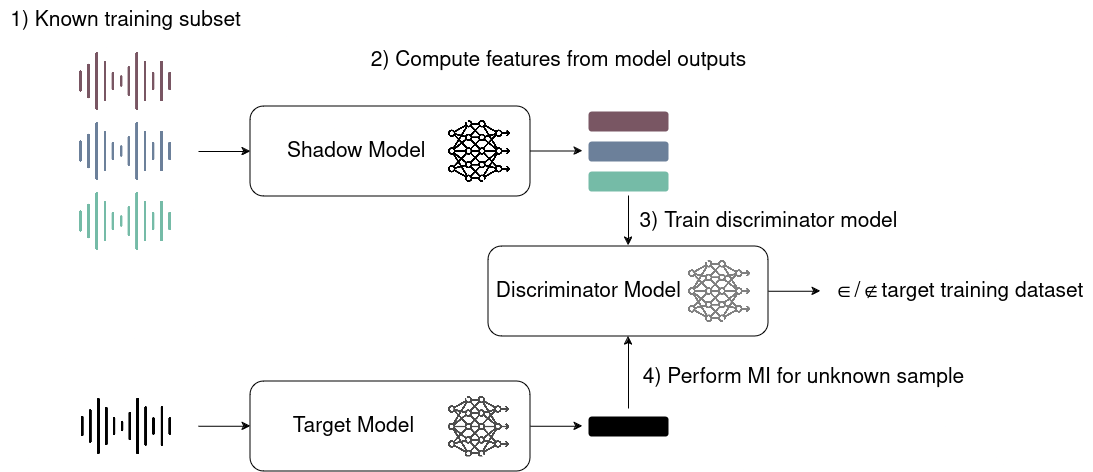
An overview of the usual approach to membership inference
In a first step, for a given set of inputs, the attacker or auditor generates outputs — in this case, transcriptions for audio files — using the shadow model. Since we know which data we have trained our model on, we can generate these outputs for both in-training and out-of-training data. Using features derived from the model outputs, we can train a discriminator model, our classifier. This classifier learns to distinguish between data points that were part of the training set and those that were not. Finally, the trained classifier is applied to the outputs of the target model, enabling the attacker or auditor to infer whether a given sample was included in the model’s training data.
Note that in an audit scenario, the shadow model can potentially be the model under investigation itself (e.g., if the auditor is the model owner or if the model owner gives the auditor access to its model and some of the training data).
Threat Model
The attacker (auditor) can access the ASR model (to varying degrees) and probes it to infer membership. Think of it like a penetration tester probing an endpoint, not from inside the system, but with enough context and access to properly imitate an attacker.
We primarily focused on the grey-box setting, which is highly relevant for real-world scenarios like third-party audits or red-teaming testing inside organizations: Here, the attacker knows some training details, but not the hyper parameters.
Core Ideas
The core contribution of the paper is the development of more effective techniques for determining whether an ASR model has “seen” a particular audio sample during training.
Going Beyond WER: Loss-Based Features
Traditionally, researchers have used the Word Error Rate (WER), the difference between a model’s transcription and the ground truth, as a signal for membership inference. In our paper, however, we argue that WER may not be enough when dealing with real-world data variations.
Instead, we propose loss-based features that measure the model’s internal confidence:
- CTC loss (Connectionist Temporal Classification): A loss function designed for sequence tasks like speech-to-text. It quantifies how well the predicted transcript matches the expected output, even when the exact alignment is unknown.
- KL divergence: Measures how much the model’s output distribution diverges when input audio is perturbed. Higher divergence suggests that the input is unfamiliar to the model (i.e., not seen during training).
These features give a much more fine-grained signal than transcription errors, and they’re especially powerful when combined with input perturbations.
Perturbing Inputs to Improve the Feature Set
Perturbing the input audio helps reveal membership. To show this, we applied two main techniques:
- Gaussian noise: Adding small, random noise to the input. For data the model was trained on, the output stays relatively stable. For unseen data, small perturbations can throw the model off, much like a cache-timing attack revealing microarchitectural secrets.
- Adversarial samples: Crafted perturbations designed to elicit the maximum change in output. These sharpen the contrast between seen and unseen samples.
The key idea here is to also take into consideration what happens to a randomly perturbed (Gaussian noise) input or an input crafted in such a way a to cross the decision boundary (adversarial noise). Perturbation exposes this behavioural asymmetry.
Evaluation and Findings
We used an encoder-decoder transformer model, trained on parts of the “LibriSpeech” dataset, as our target ASR model. We ran extensive experiments with three different shadow models (trained on other parts of the “LibriSpeech” dataset) to evaluate two types of membership inference:
- Sample-level inference: “Was this exact recording part of the training data?”
- Speaker-level inference: “Was this person’s voice used to train the model?”
Our results revealed that loss-based features consistently outperformed purely error-based ones (the WER), especially in grey-box settings: We could achieve an accuracy of up to 87% on sample-level MIA and up to 79% on speaker-level MIA under a grey-box scenario considering the Gaussian-perturbed samples, which may even be slightly improved in a white-box scenario additionally considering the adversarial samples. We also saw that sample-level MIAs were highly effective, often achieving strong precision-recall scores, while speaker-level MIAs were slightly more difficult. A possible reason for this contrast is that while ASR models are trained to minimise the loss of specific samples, the model’s training process does not explicitly account for speakers (it’s meant to recognize the spoken text).
We can also highlight two intuitive key findings: (1) The more similar the target model is to the shadow model, the more effective the MIA becomes; and (2) in a sample-level MIA, longer audio files are easier to distinguish (basically, the longer I speak, the more unique is my audio file potentially).
Take Away
This research lands at the intersection of machine learning security and privacy auditing. And it carries a few lessons for those of us responsible for securing ML-enabled systems:
- Models are part of the threat surface: If you’re deploying ASR systems (whether in call centers, virtual assistants, or internal tools) your models might be exposing training data even if your infrastructure is locked down.
- Auditing tools are emerging: What penetration testing is for web apps, this kind of auditing could become for ML systems to test whether your model is leaking training membership.
- Compliance teams will (hopefully) start asking questions: Regulators are more and more considering ML privacy issue. Knowing how to audit for training data leakage may soon be part of ML model governance toolkits.
Conclusion
This research doesn’t just point out a theoretical risk; it provides a concrete methodology for auditing ASR models. It’s a form of model introspection that helps determine whether a deployed system may inadvertently leak training data.
And from a security standpoint, it introduces another dimension of model exposure risk. If your ASR model is externally accessible, it’s not just the API endpoint that needs defending; it’s the model’s own learned behaviour.
Resources
- Francisco Teixeira, Karla Pizzi, Raphaël Olivier, Alberto Abad, Bhiksha Raj, and Isabel Trancoso. Exploring features for membership inference in ASR model auditing. Computer Speech & Language, 95, 2026.